
In a previous blog post, we announced that Embecosm will be hosting two projects for the 2021 Google Summer of Code (GSOC). You can read more about GSOC itself here, details of the application process for students here, and find more details about Embecosms proposed projects here, as well as in our last blog post.
These GSOC projects are based on work done by Embecosm collaborating with Southampton University as an industrial partner for it’s MEng final year Group Design Projects. The scope of this work was to create a RISC-V based instruction set extension to accelerate AI and machine learning applications. The project used the OpenHW Group’s CV32E40P core as the starting point. In 12 weeks the students were able to produce an instruction set extension that provided a 5.4x execution speed increase versus the unmodified core.
In this blog post we explore this project and the work that was done to see it to fruition in more detail. Other resources for those interested in the work are the presentation of the work at the British Computing Societies Open Source Specialist Group, and the source code for the project available on Github.
Design
The broad scope of the project was to create a RISC-V based instruction set extension to accelerate AI and Machine Learning operations. Obviously this scope is very broad, and it needed to be refined to a viable project achievable in 12 weeks. In the end, our group of students elected to focus on the acceleration of neural network inference.
The creation of an instruction set extension implies a baseline instruction to extend. In the end, in keeping with the popularity that neural network inference on small embedded devices at the edge has shown, the CV32E40P processor was selected. The CV32E40P is a small “microcontroller class” RISC-V processor designed by ETH Zurich and the university of Bologna and currently maintained by the Open Hardware Group.
Architecture & RISC-V Vector extension
Neural network inference is fundamentally realized through linear algebra in the form of matrix and vector operations, which are often not well supported by default instruction sets. A clear and natural route to improve the performance of neural network inference is to target these operations specifically.
Inside the RISC-V ecosystem, there is already significant support for this type of instruction through the RISC-V vector extension. An important design decision for the project was to what extent these should be taken advantage of versus the development of entirely new, novel instructions. Ultimately, given the scope for duplication of effort, and the time constraints of the project, the decision was made to focus on taking advantage of the RISC-V vector extension as far as possible. This presented a host of advantages:
- The RISC-V vector extension already supports assembly. This avoids the need to spend time and engineering effort on editing the assembler to support custom instructions.
- The RISC-V vector extension comes with a simulator (spike), allowing software to be tested without running it on the accelerator
- The RISC-V vector extension has existing support for multi width elements, allowing vector operations to be very parallel, and support any vector length
- The RISC-V vector extension code is independent of the hardware implementation of the vector extension
This leads to the following design:
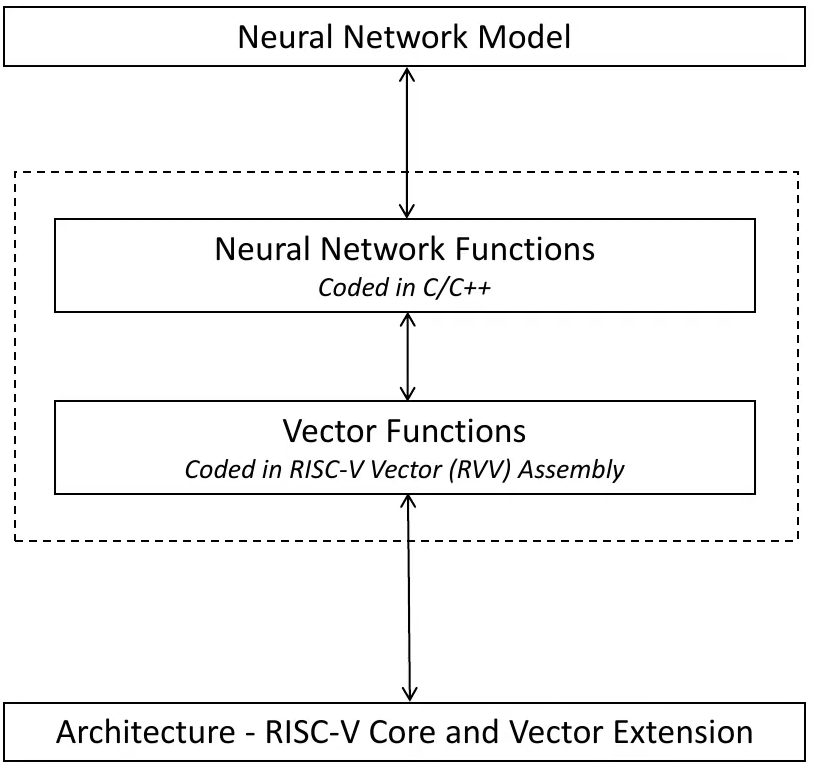
The scope of work to be done in the project is covered by the dotted area. At the top level, the system interfaces with the neural network model (programmed in TensorFlow Lite, discussed more below), and at the lowest level the system calls RISC-V Core and vector extension instructions. The system interfaces with the neural network model by providing functions for some common neural network operations, written in C/C++. These themselves take advantage of vector functions programmed in RISC-V vector assembly, which ultimately call the vector architecture specific implementations.
Choice of Operations
Common sense dictates that it makes most sense to spend time optimising the functions that are called most often. To establish these, 6 commonly used neural network models were examined to determine which functions were most commonly used. The results can be seen in Figure 2.
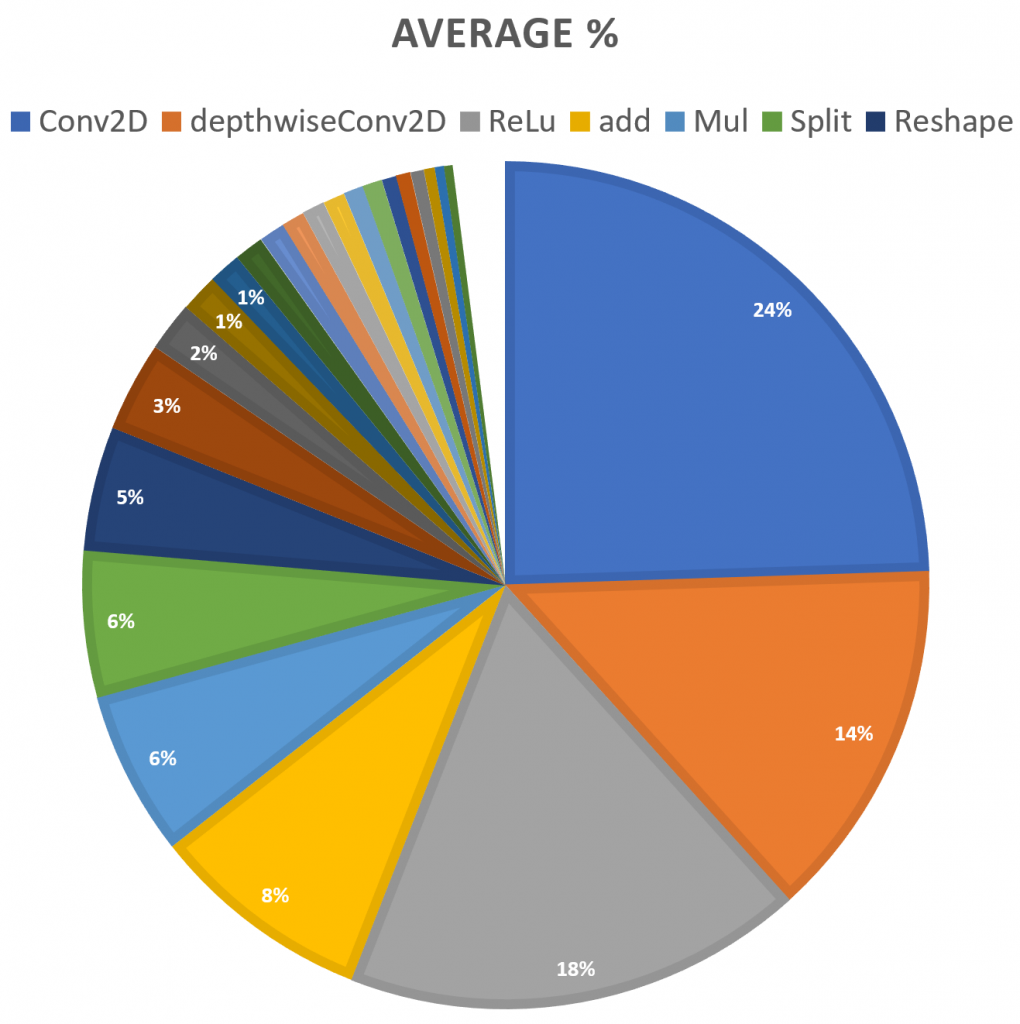
By a large majority, the most commonly used operations are the two convolution operations, taking almost a third of the total instructions. ReLu follows behind this at 18% of operations. Much further behind this are addition and multiply, at 8% and 6% each, as well as split and reshape at 6% and 5% respectively.
Of these operations, convolution, relu, addition and multiply were chosen for optimisation, leaving out split and reshape. The rationale for this was that while split and reshape are a reasonably substantial portion of the total calls, they are more software oriented operations which may not lend themselves to optimisation in the same way as the others. In addition to these operations, the pooling operation was added, as it was observed that pooling is a commonly used operation that might have been neglected in the benchmarks.
Accelerator Design
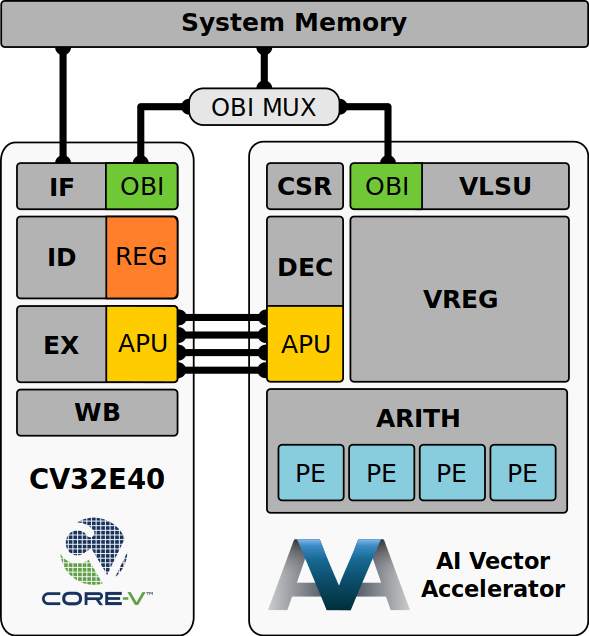
The accelerated core (see Figure 3) was designed in two parts, a modified CV32E40P (left in Figure 3) and the “AI Vector Accelerator” (right in Figure 3) that communicate via a dedicated interface (APU in Figure 3). The merit of this design is that acceleration can be achieved with minimal modifications to the CV32E40P that is already verified and known to be robust.
The baseline CV32E40P is a 32 bit in-order CPU with a 4 stage pipeline, an optional FPU and a PULP instruction set extension. In the modified CV32E40P, the PULP instruction set extension has been removed (for simplicity) and the optional FPU has been replaced with an Auxiliary Processing Unit (APU). The design of the AI Vector Accelerator can be seen in Figure 3. One notable design decision is the reimplementation of some of the CSRs required by the RISC-V vector extension. Recall that the AI vector accelerator uses the RISC-V vector extension as a basis for it’s custom instructions. It could in theory use the CSRs from the modified CV32E40P, but instead chooses to reimplement them to keep the accelerator independent. The AI Vector Accelerator also utilises a SIMD architecture and four separate processing elements, with some interesting performance implications we discuss later. The APU connects the CV32E40P and the AI vector accelerator. This APU works as a standard request/acknowledge interface. The core sends three 32-bit operands, alongside a 6 bit operand and a 15 bit flag set, and expects to get a 32 bit result and a 5 bit flag set. In this architecture, the core is completely inactive while the vector processor is executing. Some modifications are also required to support multi-cycle instructions, discussed more below.
It is worth mentioning at this point that currently this design has only been tested as a verilator model. This simplifies several aspects of the project; verilator does not model timing constraints, which simplifies several aspects of the design. For example, everything in the current implementation of the design is single cycle.
Benchmarking
TinyMLPerf
For benchmarking the tinyMLperf suite, a benchmarking suite designed for small embedded devices that is maintained by MLCommons (previously MLPerf), was used. TinyMLPerf plans to implement 3 benchmarks, reflecting common edge Machine Learning Techniques:
- Visual Wake Word
- Audio Wake Word
- Anomaly Detection
Currently, only the Visual Wake Word benchmark is implemented, and so this is the one the project was tested on.
TFL Micro
TinyMLPerf runs on TensorFlow Lite (TFL) Micro, Google’s cross-platform Machine learning toolkit for embedded devices. TensorFlow Lite is a popular implementation of TensorFlow for low powered mobile platforms that runs pre-trained TensorFlow models in a compressed format that is particularly suited for edge computing, and provides support for further compression through quantisation. TFL Micro is a reimplementation of TensorFlow Lite designed for microcontroller class devices that provides several features in addition to the ones provided by TensorFlow Lite, including:
- Static memory allocation
- Smaller Binary sizes
TinyMLPerf is based on TFL Micro, and a not insignificant part of this project is realise an implementation of TFL micro on the accelerated core.
Porting to the CV32E40P
The reference implementation of TFL micro proved very easy to port, and was achieved largely through edits to the build system with very few edits to the code. This was supported further by the presence of some existing RISC-V build infrastructure that significantly reduced the work required.
With respect to porting TinyMLPerf, almost all of the work required was the port of TFL micro, and so it was (almost) sufficient to swamp the official TFL micro repo with the ported TFL Micro fork. To assist with benchmarking, several other tasks were also completed. Firstly, a multi-platform build system was also added to build for Spike and the CV23E40P, and the optimised and unoptimized versions of those. Secondly, cycle measurements were added using the mcycle CSR, which is incremented every time a clock cycle occurs.
TFL Micro Optimisation
A key part of the project is producing the optimised version of TFL Micro that can take advantage of the new hardware. Fortunately, this proved to be easier than had initially been feared, particularly with the generous help of Pete Warden, Time Callahan and Tim Ansell who were kind enough to give some of their time to help.
TFL Micro provides a modular kernel that allows operations to be easily changed out for optimised versions. Each TFL micro kernel operation is implemented in a separate C++ file, and specific implementations can be overwritten with other versions using the appropriate build flags. Generally, this allows for streamlined integration of optimised versions of operations that can take advantage of existing unit tests, though there are some constraints on this. Most notably, new functions must maintain the top level interfaces of the old ones.
Results

The baseline CV23E40P was compared with the accelerated CV32E40P on both Spike (a functional model) and our verilator model. The results are striking, showing a 7.3x speedup on Spike and a 5.4x speedup on the CV32E40P.
Clearly, the runtime improvement on Spike is something of a best case that doesn’t have to deal with the complications of pipelines, memory bandwidth, etc., so a strong performance improvement on Spike is not itself outstanding. However, a strong performance of Spike alongside a similarly strong performance in the verlilator model of our accelerated CV32E40P is an excellent result.
It is worth acknowledging that at the time of the BCS presentation linked above, there was a disparity in the agreement of the outputs of the accelerated CV32E40P and the baseline in some invocations. At the time it was noted that this error was small, and unlikely, especially with the results from spike in mind, to be compromising the overall integrity of results. This has since been confirmed, with a fix for this error changing the relative performance of the baseline and accelerated CV32E40P insignificantly.
Discussion
In 12 weeks, a group of students from Southampton university were able to produce an AI accelerator based on the RISC-V Vector extension capable of producing a 5.4x speedup on an appropriate benchmark. This is an outstanding result for which the students, the University, and Embecosm should be extremely proud.
One of the particularly striking outcomes of this work is just how few RISC-V vector instructions were actually required by the students in order to produce such a striking result. In the end, the students only made use of 17 of the RISC-V vector instructions, a truly tiny portion of the total. As noted by the students themselves, it seems like cherry picking instructions from a larger set may be a genuinely good way of designing a custom accelerator and may potentially save a great deal of work versus designing from scratch in many applications.
An interesting aspect of the design was that integrating an accelerator into a processor requires a fairly heavy amount of CPU modification. One example of this would be the need to disable writeback signals to the scalar registers, to prevent them getting written even when there is a vector instruction overriding them. Another example would be stalling the pipeline. This is simple for the smaller instructions, but some of the memory instructions in the vector accelerator are very long indeed, and it required significant modification to get the CPU to hold long enough for them to finish executing.
Considering the above, the integration of an accelerator as a “bolt on” to an existing core is worth discussion. Given the scope of the project and time constraints the students faced, it was eminently reasonable to do things in this way. However, as the students themselves have attested, integrating an accelerator to a core not designed for it is a significant challenge. Those interested in undertaking similar projects should learn from the lessons of this work when considering their own designs.
A consideration of the existing results is that currently the accelerator exists only as a verilator model and has not been synthesised in an FPGA. This is particularly pertinent as currently, as we’ve mentioned, the complex features of the accelerator have been designed as a single-stage system with no pipeline. Analysing the accelerator and determining the critical path through it and the design of appropriate pipeline stages remains an (interesting) challenge still to be tackled. Realistically, a synthesised version of the accelerator with a proper pipeline is still likely to demonstrate a significant improvement over the baseline CPU, though one of a smaller magnitude. Our current Google Summer of Code projects following on from this work explore this possibility further.
Verification is also an important part of any project like this, and this presented a significant challenge for our students, even despite the relatively small size of the project. Aside from the changes to the CV32E40P core that needed verifying, the RISC-V vector extension has a very large number of different settings, of which every valid needs to be verified. For example, not only does each instruction need to be verified, but verified with different element widths, the number of vector registers to be included, etc. Ultimately, this makes verifying even a fairly small project like this one extremely time consuming, and indeed full verification wasn’t achievable in the timeframe.
Conclusion
In just 12 weeks, our group of Southampton students produced an instruction set extension for the CV32E40P core based on the RISC-V vector extension that demonstrated over a 5 fold increase in performance over the baseline core. This project was very successful, but there remain several outstanding avenues for improvement, the most immediate of which is likely to be to synthesise the core on an FPGA to examine how the performance improvements affect real hardware.
The project continues through the 2021 Google Summer of Code, tackling this problem of FPGA synthesis. If this sounds like it would be of interest to you, more details can be found on the projects page here.